Linear regression requires that the predictors and response have a linear relationship. This assumption holds if the residuals are zero on average, no matter what values the predictors \( X_1, \dots, X_p \) take. Often it's also assumed that the residuals are independent and normally distributed with the same variance (homoskedasticity), so that we can contruct prediction intervals, for example. To check whether these assumptions hold, we need to analyse the residuals. In statistical arbitrage, residual analysis can also be used to generate signals.
The residuals of a linear model usually has a normal distribution. We can plot the residual's density to check for normality:
plt.figure() #ols.fit().model is a method to access to the residual. fama_model.resid.plot.density() plt.show()
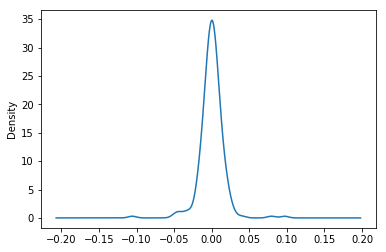
As seen from the plot, the residual is normally distributed. By the way, the residual mean is always zero, up to machine precision:
print 'Residual mean:', np.mean(fama_model.resid) [out]: Residual mean: -2.31112163493e-16 print 'Residual variance:', np.var(fama_model.resid) [out]: Residual variance: 0.000205113416293
This word is difficult to pronounce but not difficult to understand. It means that the residuals have the same variance for all values of X. Otherwise we say that 'heteroskedasticity' is detected.
plt.figure(figsize = (20,10))
plt.scatter(df.spy,simple.resid)
plt.axhline(0.05)
plt.axhline(-0.05)
plt.xlabel('x value')
plt.ylabel('residual')
plt.show()
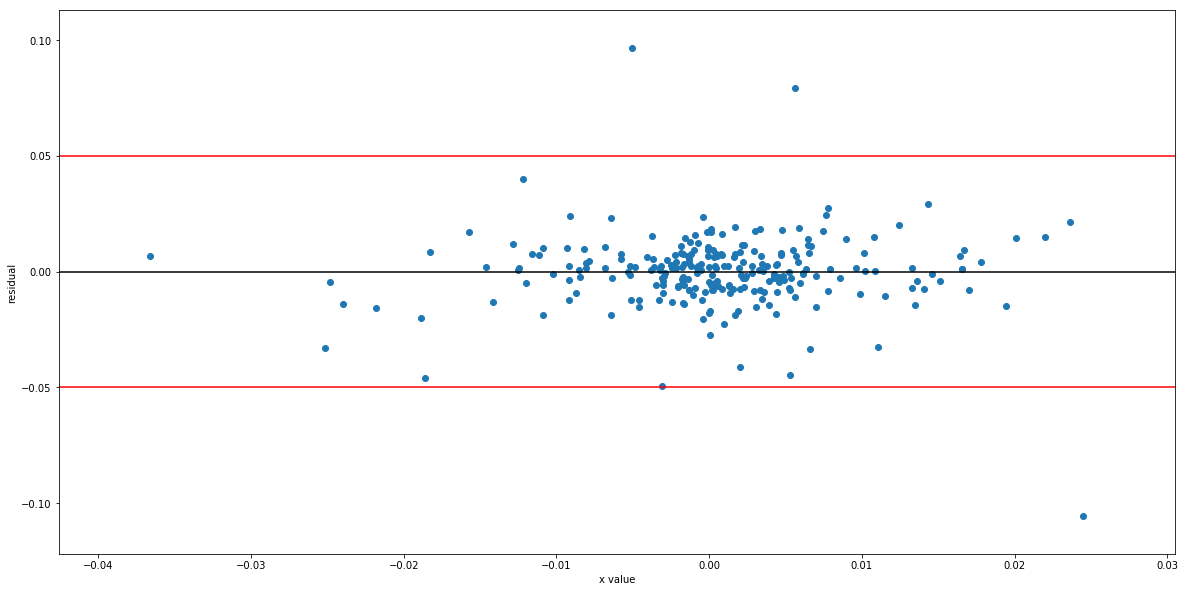
As seen from the chart, the residuals' variance doesn't increase with X. The three outliers do not change our conclusion. Although we can plot the residuals for simple regression, we can't do this for multiple regression, so we use statsmodels to test for heteroskedasticity:
from statsmodels.stats import diagnostic as dia het = dia.het_breuschpagan(fama_model.resid,fama_df[['MKT','SMB','HML','RMW','CMA']][1:]) print 'p-value: ', het[-1] [out]:p-value of Heteroskedasticity: 0.144075842844
No heteroskedasticity is detected at the 95% significance level.